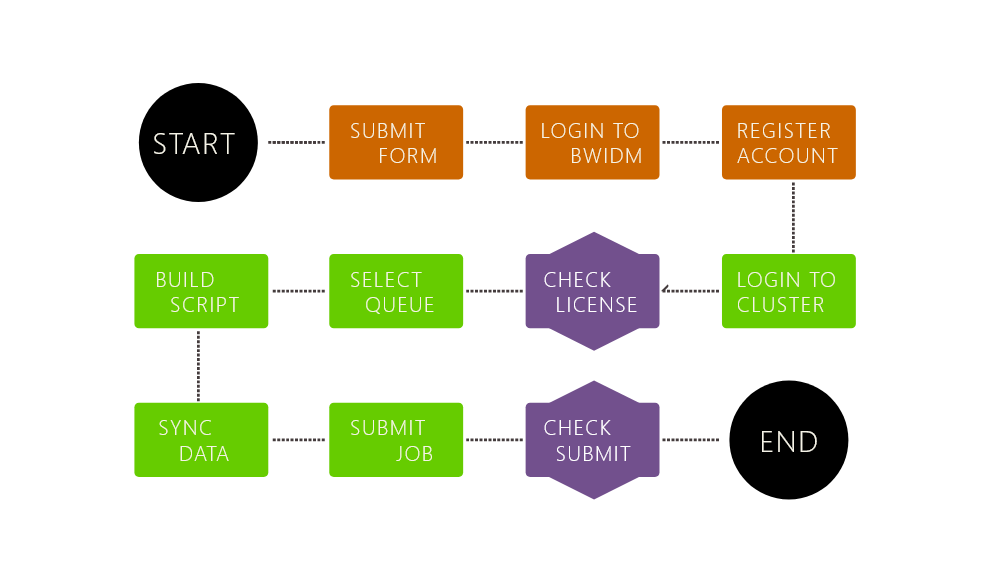
Registration and Login
bwUniCluster 2.0 offers a detailed, well documented and kept updated wikipage.
Here you'll find the right steps to register on the platform, login options from Linux, MacOS or Windows and first steps on the cluster.
A Presentation in german, by Prof. Rainer Keller, shows step by step bwUniCluster 2.0 registration process.
Before you start the registration process on BWIDM-server you will first need to get bwUniCluster entitlements issued by your home university.
Hochschule Esslingen offers these entitlements after submitting the following formular to the information center (Rechenzentrum).
Download formular
Note: do not forget to answer the survey after the registration to get access to bwUniCluster resources.
File Systems
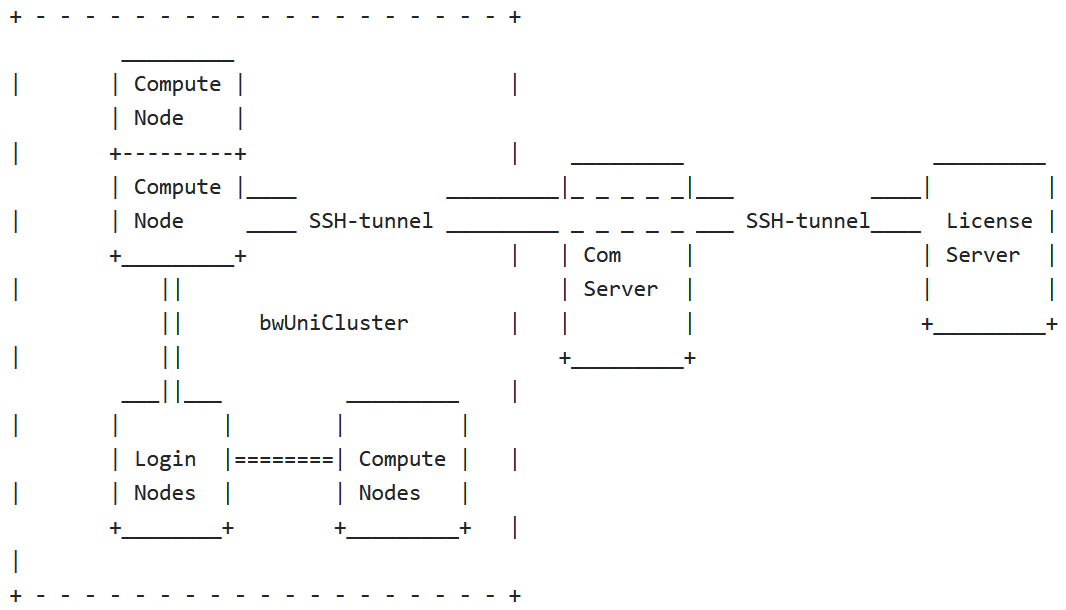
In addition to high-performance computing resources, the bwUniCluster hardware architecture includes a parallel hardware Lustre file system that is connected to the computing nodes via a high-end InfiniBand fiber-optic network.
As a result, not all data is securely backed up or stored on the cluster. And you, the user, have to decide how best to store your data to take full advantage of the parallel file system or the backup capabilities of the cluster.
The following data storage systems are offered on the cluster with some recommendations:
- $HOME folder - suitable for permanently required data. The user can access this folder from all cluster nodes and a regular backup of the data in this folder is carried out automatically. But it has a qouta limit. It is therfore recomended, that you keep in the $HOME directory the files that you regularly use. Like for example, configuration files, source code, executable programs, etc.
The default limit quota for the $HOME directory, on the cluster is 1 TiB and 10 million inodes (files or folders) per user. To check the current quota usage and limit, use the command:
| lfs quota -uh $(whoami) $HOME |
In addition to the quota limit per user, there is a limit per university, which is based on the financial share of the universities for the bwUniCluster. The following command will show your this quota:
| lfs quota -ph $(grep $(echo $HOME | sed -e "s|/[^/]*/[^/]*$||") /pfs/data5/project_ids.txt | cut -f 1 -d\ ) $HOME |
- Workspaces - a parallel file system designed for parallel data access and high throughput of large files. It is able to provide parallel data access with transfer rates of up to 54 GB/s for writing and reading. It is perfectly designed for storing large, non-permanent data sets, e.g. restarting files or output data that have to be post-processed.
Workspaces have a lifetime, and when it expires, the data on it is permanently removed. The maximum lifespan of a workspace is 60 days, but it can be extended three times at the end of this period for a maximum of 240 days after the workspace is created. If a workspace accidentally expires, the data can still be restored for a limited time (a few weeks). In this case you should create a new workspace and state the name of the new and the expired one in a ticket or by e-mail to the bwUniCluster hotline.
You can find more information about creating and managing workspaces here.
- $TMP folder - a local node directory on bwUniCluster. While all tasks of a parallel application access the same $HOME and Workspace directory, the $TMP directory is only local to the specific node on the cluster. Different tasks of a parallel application may and should use different directories in a multi-node run. This is exactly the folder that should be used for temporary files accessed by individual tasks. All nodes have fast SSDs local storage devices that are used to store data in $TMP.
You can always find detailed information on file systems on the official wiki page of bwUniCluster.
Job submittion queues (partitions)
As a general purpose type of cluster, bwUniCluster offers a platform for a multitude of jobs which may differ in the required compute resources, such as needed processing CPU power, quantity of RAM, GPU power, (wall-) time etc.
For better allocation of hardware resources to specific jobs, a queue partitioning system is offerd to the user, which have to assign his jobs manually to the specific queue (aka partition).
The job can be asigned to a specific queue with the command sbatch -p queue_name or in a script through #SBATCH --partition=queue_name option.
Note: The specification of a queue is obligatory on bwUniCluster!
| Queue name | Node | Default resources | Minimum resources | Maximum resources |
| dev_single | thin | time=00:10:00, mem-per-cpu=1125mb | | time=00:30:00, nodes=1, mem=180000mb,ntasks-per-node=40, (threads-per-core=2) 6 nodes are reserved for this queue. Only for development, i.e. debugging or performance optimization ... |
| single | thin | time=00:30:00, mem-per-cpu=1125mb | | time=72:00:00, nodes=1, mem=180000mb, ntasks-per-node=40, (threads-per-core=2) |
| dev_multiple | hpc | time=00:10:00, mem-per-cpu=1125mb | nodes=2 | time=00:30:00, nodes=4, mem=90000mb, ntasks-per-node=40, (threads-per-code=2) 8 nodes are reserved for this queue. Only for development, i.e. debugging or performance optimization ... |
| multiple | hpc | time=00:30:00, mem-per-cpu=1125mb | nodes=2 | time=72:00:00, mem=90000mb, nodes=80, ntasks-per-node=40, (threads-per-core=2) |
| dev_multiple_il | IceLake | time=10, mem-per-cpu=1950mb | nodes=2 | time=30, nodes=8, mem=249600mb, ntasks-per-node=64, (threads-per-core=2) 8 nodes are reserved for this queue. Only for development, i.e. debugging or performance optimization ... |
| multiple_il | IceLake | time=10, mem-per-cpu=1950mb | nodes=2 | time=72:00:00, nodes=80, mem=249600mb, ntasks-per-node=64, (threads-per-core=2) |
| dev_gpu_4_a100 | IceLake + A100 | time=10, mem-per-gpu=127500mb, cpus-per-gpu=16 | | time=30, nodes=1, mem=510000mb, ntasks-per-node=64, (threads-per-core=2) |
| gpu_4_a100 | IceLake + A100 | time=10, mem-per-gpu=127500mb, cpus-per-gpu=16 | | time=48:00:00, nodes=9, mem=510000mb, ntasks-per-node=64, (threads-per-core=2) |
| gpu_4_h100 | IceLake + H100 | time=10, mem-per-gpu=127500mb, cpus-per-gpu=16 | | time=48:00:00, nodes=5, mem=510000mb, ntasks-per-node=64, (threads-per-core=2) |
| fat | fat | time=00:10:00, mem-per-cpu=18750mb | mem=180001mb | time=72:00:00, nodes=1, mem=3000000mb, ntasks-per-node=80, (threads-per-core=2) |
| dev_gpu_4 | gpu_4 | time=00:10:00, mem-per-gpu=94000mb, cpus-per-gpu=10 | | time=30, nodes=1, mem=376000, ntasks-per-node=40, (threads-per-core=2) 1 node is reserved for this queue. Only for development, i.e. debugging or performance optimization ... |
| gpu_4 | gpu_4 | time=00:10:00, mem-per-gpu=94000mb, cpu-per-gpu=10 | | time=48:00:00, mem=376000mb, nodes=14, ntasks-per-node=40, (threads-per-core=2) |
| gpu_8 | gpu_8 | time=00:10:00, mem-per-gpu=94000mb, cpu-per-gpu=10 | | time=48:00:00, mem=752000mb, nodes=10, ntasks-per-node=40, (threads-per-core=2) |
Submitting a job using sbatch
sbatch - a linux command to submit a batch script to Slurm workload manager which allocates nodes to the users. The batch script may be given to sbatch through a file name on the command line or directly into standart input.
sbatch will read any options in the batch script's which start with prefix #SBATCH.
sbatch will create a job reading the batch script and allocate resources accordingly. The resources though won't be granted immediately, the job may sit in a pending queue till its required resources become available.
Example using sbatch
Let's say you want to run a script wich will echo "Hello world!" on 2 processors using mpirun.
Here is an example of such a script, named hello.sh:
#!/usr/env/bin bash
mpirun -n 2 echo "Hello, world!" |
To run this script on bwUniCluster, you must first provide some #SBATCH options. Such as:
- Number of nodes to allocate. In this case in need 1: #SBATCH --nodes=1
- Number of cpus. In this case 2: #SBATCH --ntasks-per-node=2
- Queue or partition name on the cluster: #SBATCH --partition=single
- Maximum runtime in DD:HH:MM:SS. In this case 1 minute is enough: #SBATCH --time=1:00
- etc
Your new hello.sh script will look like:
#!/usr/env/bin bash
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=2
#SBATCH --partition=single
#SBATCH --time=1:00
module load compiler/gnu/4.8.5
module load mpi/openmpi/4.0
mpirun -n 2 echo "Hello, world!" |
Where module load loads the required software to run your mpirun programm.
Now, to submit your hello.sh script to the cluster job scheduler you may run, from the folder hello.sh is located:
sbatch optiopns
- Script prefix are options you may include in your script header
- These options may be provided directly in the command line after sbatch command. You use the same options mentioned in the header without #SBATCH prefix.
| sbatch --time=1:00 --partition=single hello.sh |
| Script header options | Purpose |
| #SBATCH --partition=queue-name | Name of the queue for resource allocation. It is mandatory to set the right queue name |
| #SBATCH --time=time | Maximum time limit in format DD:HH:MM:SS |
| #SBATCH --nodes=number | Number of nodes to allocate |
| #SBATCH --ntasks=number | Total number of tasks to be allocated. By default each task has 1 cpu. |
| #SBATCH --ntasks-per-node=number | Number of tasks per node. Total being this number multiplyed by the number of nodes. Max either 28 or 40 depending on partition. |
| #SBATCH --cpus-per-task=number | Number of CPU per task. Default is 1. |
| #SBATCH --mem=value_in_MB | Maximum memory per node. Default is either 128000 or 96000 MB, depending on partition |
| #SBATCH --output=file_name | Name of the file to store output in. |
| #SBATCH --error=file_name | Name of the file for storing errors |
| #SBATCH --mail-type=event | Send an email when certain events occur. Valid events: NONE, BEGIN, END, FAIL, REQUEUE, ALL |
| #SBATCH --mail-user=mail-address | User email address to send messages to |
| #SBATCH --job-name=name | Job name |
See available resources on partitions (queues)
sinfo_t_idle - a linux wrapper command to show a list of partitions on the cluster and idle nodes on it
An example of the output of such a command will be:
$ sinfo_t_idle
Partition dev_single : 6 nodes idle
Partition single : 25 nodes idle
Partition dev_multiple : 8 nodes idle
Partition multiple : 0 nodes idle
Partition fat : 2 nodes idle
Partition dev_gpu_4 : 1 nodes idle
Partition gpu_4 : 3 nodes idle
Partition gpu_8 : 1 nodes idle
Partition dev_multiple_i : 0 nodes idle
Partition multiple_il : 1 nodes idle
Partition dev_gpu_4_a100 : 1 nodes idle
Partition gpu_4_a100 : 1 nodes idle
Partition gpu_4_h100 : 0 nodes idle |
Here you can see how many nodes are idle (free) on each partition (queue) and ready for immediate use.
List user's submitted jobs
squeue - displays information about user's specific active, pending and/or recently completed jobs
squeue -l will give you a more detailed information.
Job information
scontrol show job <JOBID> displays job's state information and diagnostic output for jobs with Id, JOBID
JOBID you'll get when you submit a job with sbatch or from squeue information table
To get more detailed output you can use -d option, such as for example if JOBID is 8888888, to get the detailed data do:
| scontol -d show job 8888888 |
Cancel jobs
scancel <JOBID> will cancel jobs with Id, JOBID.
scancel -t <STATE> will cancel all the jobs in a certain STATE. It can be PENDING, RUNNING or SUSPENDED
Chain jobs
Some jobs require more time to finish than the maximum walltime a single job is allowed to run. As a solution it is possible to run multiple jobs in a chain, meaning next job will start only if the previous one is completed.
-d, --dependency=<dependency_list> is an option for sbatch command that deffer the start of this job until the specified dependencies have been satisfied / completed.
<dependency_list> is of the form <type:job_id[:job_id][,type:job_id[:job_id]]> or <type:job_id[:job_id][?type:job_id[:job_id]]>. All dependencies must be satisfied if ',' separator is used. And any dependency must be satisfied if '?' separator is used. Once a job dependency fails due to the termination state of preceding job, the depending job will never run.
Some useful dependency types to use in <dependency_list>:
| Dependency | Purpose |
| after:job_id[[+time][:job_id[+time]...]] | After the specified jobs start or are canceled and 'time' in minutes from job start or cancelation happens, this job can begin execution. If no 'time' is given then there is no delay after start or cancelation. |
| afterany:job_id[:job_id...] | This job can start after specified jobs are over. |
| afternotok:job_id[:job_id...] | This job can start after specified jobs have terminated in some failed state. Ex: node failure, non-zero exit code, time out etc. |
| afterok:job_id[:job_id...] | This job can start after specified jobs executed successfully. Ex: completed with exit code of zero |
Knowing that a job submited with sbatch will output the following string:
| Submitted batch job JOB_ID |
It is possible to cut the string to get job ID into a variable named job_id with the following submit command, where hello.sh is the name of the job script you want to run:
| job_id=$(sbatch hello.sh) && job_id=${job_id#'Submitted batch job '} |
Now you can run a while loop in a bash script to submit multiple chain jobs:
#!/usr/bin/env bash
job_sbatch_script="hello.sh"
declare -i nr_of_jobs="5" # how many chain jobs you want to run
dependency_type="-d afterok"
declare -i loop_counter="1"
while [[ ${loop_counter} -le ${nr_of_jobs} ]]; do
if [[ ${loop_counter} -eq 1 ]]; then
sbatch_options=""
else
sbatch_options="${dependency_type}:${job_id}"
fi
job_id=$(sbatch ${sbatch_options} ${job_sbatch_script}) && job_id=${job_id#'Submitted batch job '}
echo "Submitted batch job ${job_id}"
loop_counter=$(( ${loop_counter} + 1 ))
done |